Technology hardware upgrades data center operation in 2026

Artificial Intelligence continues to redefine what’s possible — from generative reasoning models to real-time robotics and automation. Yet, behind every breakthrough is a quiet revolution happening at the infrastructure layer. Data centers worldwide are transforming how compute is powered, cooled, and scaled — enabling the high-density environments required for AI and accelerated workloads.
This blog explores the newest advancements in GPU design, rack engineering, and power architecture — innovations shaping the next era of intelligent computing.
The GPU Revolution: From Graphics to Intelligence
The development of GPUs has fundamentally changed the computing environment, especially in the areas of machine learning (ML) and artificial intelligence (AI). GPUs do thousands of jobs concurrently, in contrast to conventional CPUs, which operate slowly. They are perfect for data-intensive activities like neural networks, deep learning, and real-time inference because of their parallelism.
The most sophisticated AI models available today, such as generative transformers and real-time computer vision systems, are powered by GPUs. They are essential for AI training and inference because of their architecture, which is designed to handle large parallel calculations.
Did you know that? According to MarketsandMarkets the GPU as a Service (GPUaaS) industry is expected to expand at a compound annual growth rate (CAGR) of around 26.5% from $8.81 billion in 2025 to $26.62 billion by 2030.
GPUs must thus be given top priority in your computing strategy, regardless of whether you’re creating a chatbot, fraud detection system, or self-driving algorithm.
Understanding GPU progress is essential if you intend to grow your AI or ML projects. It will assist you in selecting the appropriate infrastructure, shortening time-to-market, and lowering computational expenses. Let’s now explore the deep knowledge pool. The initial purpose of GPUs was to enhance graphics rendering for movies and gaming. They mostly used fixed-function pipelines to service consumer markets in the early 2000s. But when researchers found that GPUs could also speed up general-purpose scientific computations, the industry experienced a sea change.
The initial purpose of GPUs was to enhance graphics rendering for movies and gaming. They mostly used fixed-function pipelines to service consumer markets in the early 2000s. But when researchers found that GPUs could also speed up general-purpose scientific computations, the industry experienced a sea change.
In 2006, NVIDIA announced CUDA, which was a turning point in the development of GPUs. A new age of general-purpose GPU computing (GPGPU) was ushered in with CUDA, which allowed programmers to create parallel code for GPUs. GPUs were soon used by AI researchers to speed up deep learning tasks.
Because GPUs can effectively manage parallel workloads, they perform better than CPUs in AI and ML. A GPU has hundreds of tiny cores designed for processing data simultaneously, whereas a CPU may have 8 or 16 cores suited for sequential work.
For deep learning jobs that require processing big matrices, performing backpropagation, and training intricate models, this architectural architecture is perfect. By drastically cutting down on model training time, GPUs also allow ML developers to use quicker iteration cycles.
Additionally, dedicated memory and high bandwidth are features of contemporary GPUs. During training and inference, it guarantees that there are few data bottlenecks. GPUs are the best option for AI workloads because of these benefits.
CPU vs GPU vs TPU: Which is Best for You?
| Factor | CPU (Central Processing Unit) | GPU (Graphics Processing Unit | TPU (Tensor Processing Unit) |
| Designed For | General-purpose computing and control logic | Parallel processing, graphics rendering, compute-heavy tasks | High-speed matrix math for AI/ML workloads |
| Core Strength | Serial processing and versatile task execution | Massive parallelism for AI training and rendering | Tensor operations acceleration for deep learning |
| Parallelism | Limited (few cores, high clock speed) | Very high (thousands of small cores) | Extremely high and optimized for tensor math |
| Training Speed (AI/ML) | Slow; not ideal for deep models | Fast; accelerates training significantly | Very fast; best for TensorFlow-based models |
| AI/ML Suitability | Basic or non-critical workloads | General-purpose AI/ML tasks | TensorFlow-specific large-scale AI workloads |
Rack Innovations: Building Infrastructure for High-Density AI Compute
As GPU performance scales, the pressure shifts to the physical rack environment. AI racks are now crossing 80 – 150 kW power envelopes — far beyond what traditional air-cooled systems can support.
Purpose-Built AI Racks
New trends include:
- Shortened airflow travel distances for reduced thermal resistance
- Optimized cable architecture to handle extreme node-to-node interconnects
- Dynamic rack provisioning based on training vs inference workloads
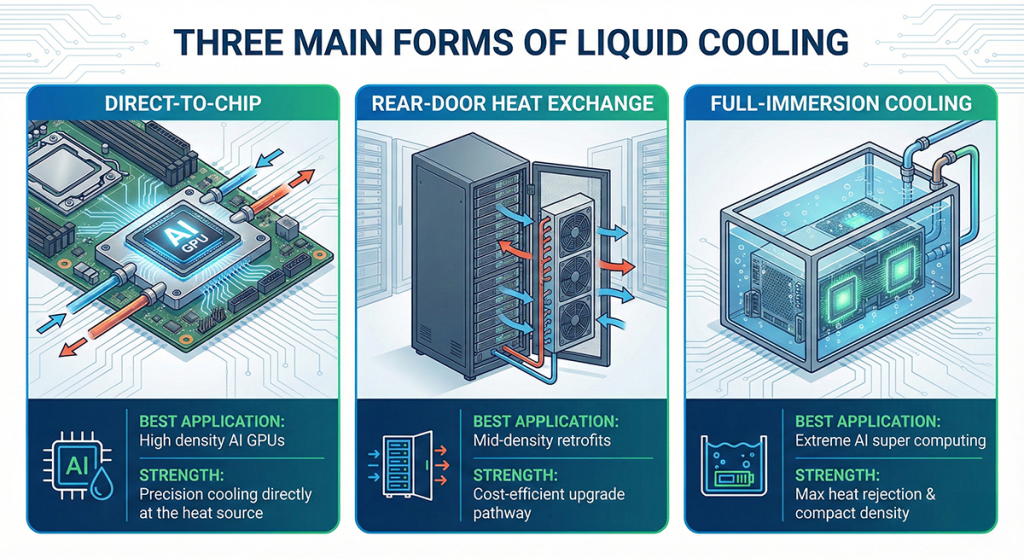
Liquid cooling plays a pivotal role here — ensuring GPUs maintain peak performance without thermal throttling. Major hyperscale’s are rapidly phasing in designs supporting direct-to-chip cooling, rear door heat exchangers, and immersion cooling for dense AI clusters.
Liquid Cooling: The New Thermal Gold Standard
Air cooling has reached its physical limits. Modern GPU accelerators often exceed 1000W of heat dissipation per device, which conventional airflow cannot manage without throttling. Liquid cooling is now essential for AI infrastructure because it enables:
- Up to 4X better heat removal versus air cooling
- Lower operational footprint and acoustic output
- Longer component lifespan due to stable thermals
Data centers using liquid cooling consistently report higher training stability and performance predictability — crucial for industries like healthcare, BFSI, and autonomous systems where uptime is non-negotiable.
Power Architecture Evolution: Supporting High-Density AI
Today’s power architectures face timing, conversion, and distribution efficiency challenges. Traditional 12V systems introduce losses during long runs to high-power GPUs.
AI-first data centers are transitioning to 48V power distribution, offering:
- Reduced transmission losses over greater distances
- Superior conversion efficiency for GPUs and accelerators
- Better scalability for 80–150 kW rack densities
Manufacturers like Renesas are advancing Digital Power Modules (DPMs) for responsive load balancing — enabling real-time power optimization depending on GPU utilization levels.
Energy Efficiency & Sustainability Pressures
Massive GPU clusters demand enormous energy. Analysts estimate AI data center power consumption will soar globally — crossing 3–4% of all electricity usage in the next few years.
To counter this, data centers are deploying:
- AI-based thermal optimization
- Dynamic power gating inside accelerator chips
- Software-driven orchestration for sustainable peak performance
Energy-proportional computing will define the coming decade — ensuring compute consumption matches real-time business value.
Explore AI-Aligned Data Center Infrastructure with ESDS
Enterprises are expanding AI workloads across hybrid environments, which is increasing the need for efficient power usage, optimized cooling, and higher compute density. ESDS provides data center infrastructure designed to support such operational requirements.
ESDS offers:-
- Tier III compliant data center facilities in India
- Infrastructure integration options for advanced cooling technologies
- Power management and security measures aligned with regulated industries
- Cloud and colocation services suitable for BFSI, Government, and Enterprise workloads
For more information about ESDS’ data center infrastructure and service capabilities: https://www.esds.co.in
Conclusion: Hardware Determines the Future of AI
Software innovation grabs the headlines — but hardware innovation decides how far AI can truly go.
Enterprises investing in advanced rack engineering, GPU scaling, and future-ready power architectures will gain:
- Greater inference density per rack
- Lower operational overheads and carbon footprint
- Faster deployment of high-value AI services
The organizations modernizing infrastructure today are the ones defining the future of intelligent technology.