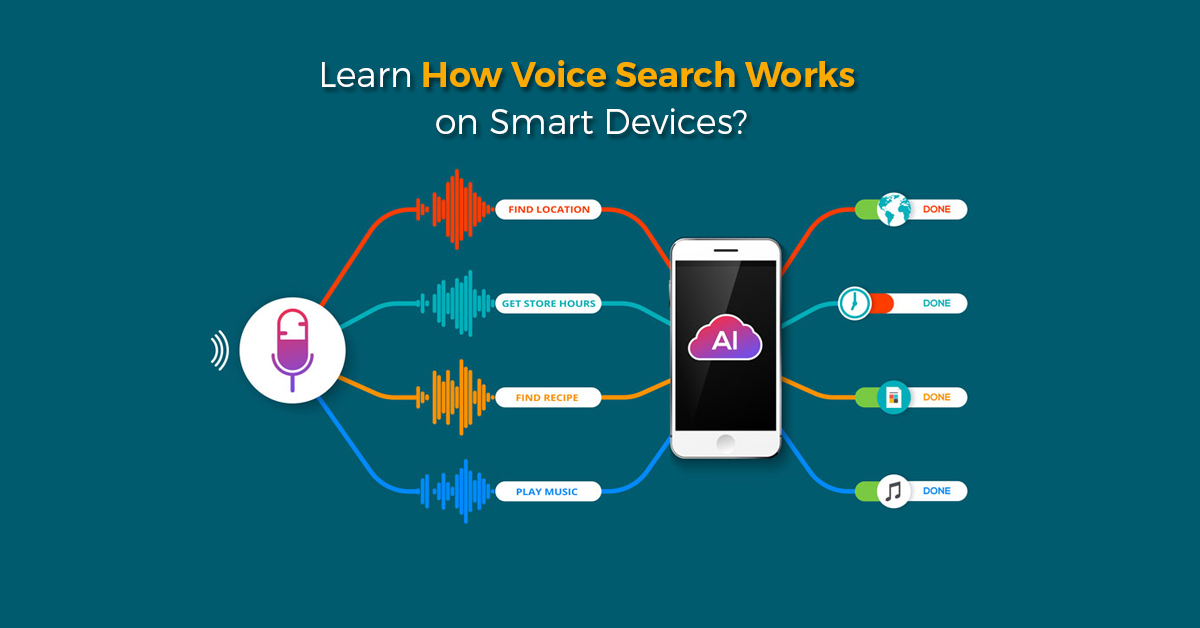
Your Voice Matters – How does Voice Search Work on Smart Devices?
Using voice search to interact with smart devices is what we are doing in our daily lives. Initially, it began with using voice search on phones, and later we got accustomed to smart watches, smart speakers, car speakers and much more.
Several cloud platforms like Apple’s Siri, Google Assistant, Microsoft Cortana, and Amazon Alexa are gaining praises for giving us this facility but, the real hero is Edge Computing. This technology plays a vital role in enabling these voice search interfaces. There goes an extensive amount of analysis inside the devices for processing the voices, languages, and accents of the users.
Let’s drill down the process of voice search in depth –
Detection of Keywords
Voice search is becoming a significant part of digital marketing and hence, the importance of keywords which people majorly use. So, when you do a voice search, the voice-enabled devices do not always records and ask the cloud whether someone is giving them any instructions. The process of recording and sending it back and forth would take a lot longer, adding to latency and affecting the response time. And, not just that, the privacy, energy, all the resources would get wasted too.
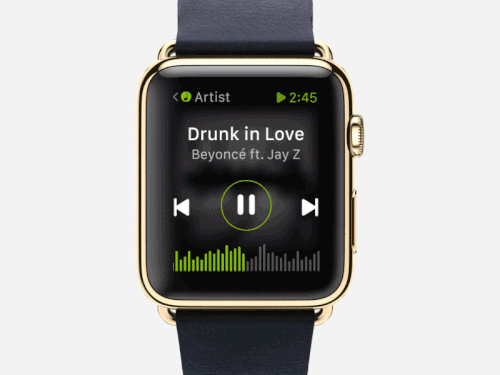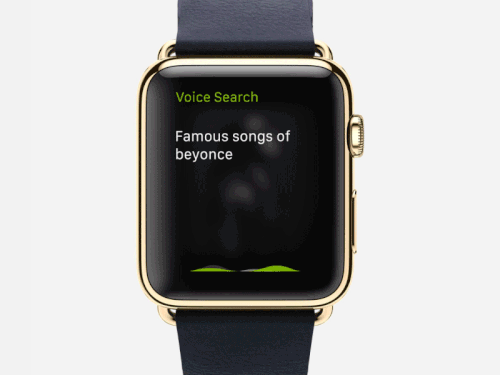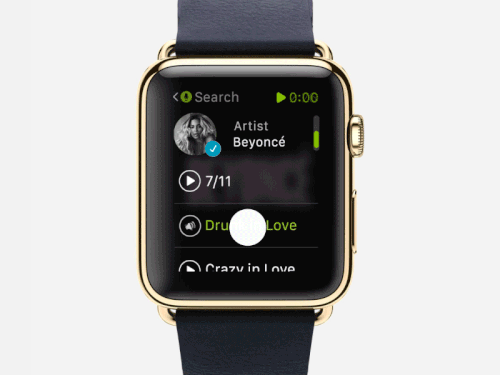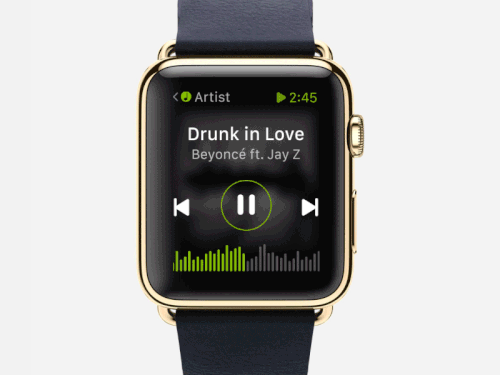
The voice-adaptive interfaces usually use the “wake-word” detection technique, which does the processing by using a few edge computing resources; at the edge or device itself. In this manner, the devices process the microphone signals not disturbing the complete system. This approach is highly power-efficient and enhances the usage time of the smart devices, which require batteries to function.

During the core handling of the wake-word detection, a digital signal processor (DSP) gets a match with the most-expected word. Further, it sends signals to the complete system that it needs more computing power for capturing audio, processing language and accent, tracing voice, and transmitting it after compression.
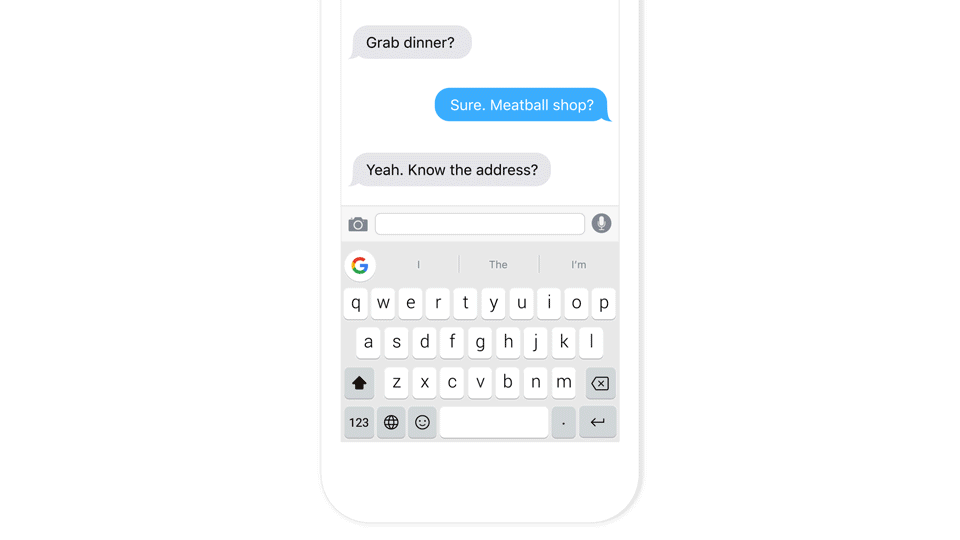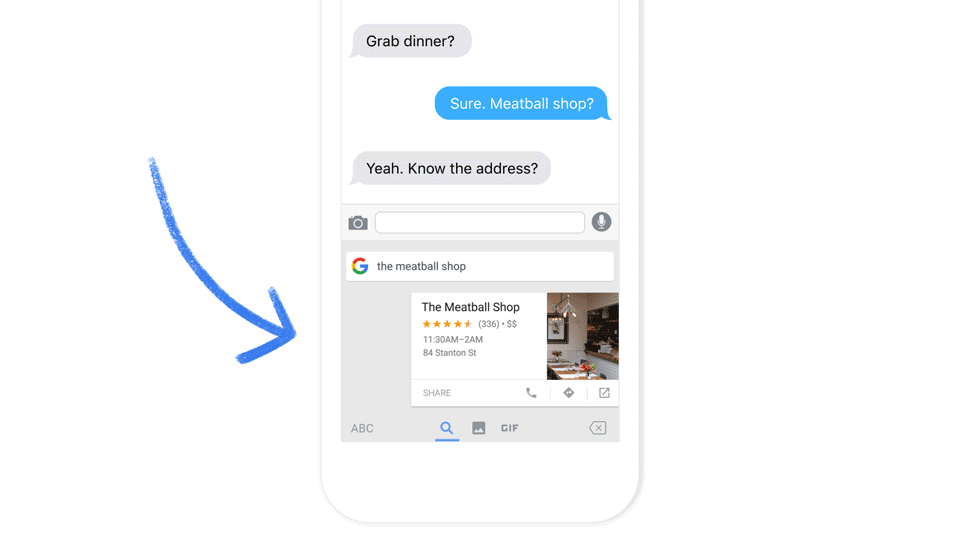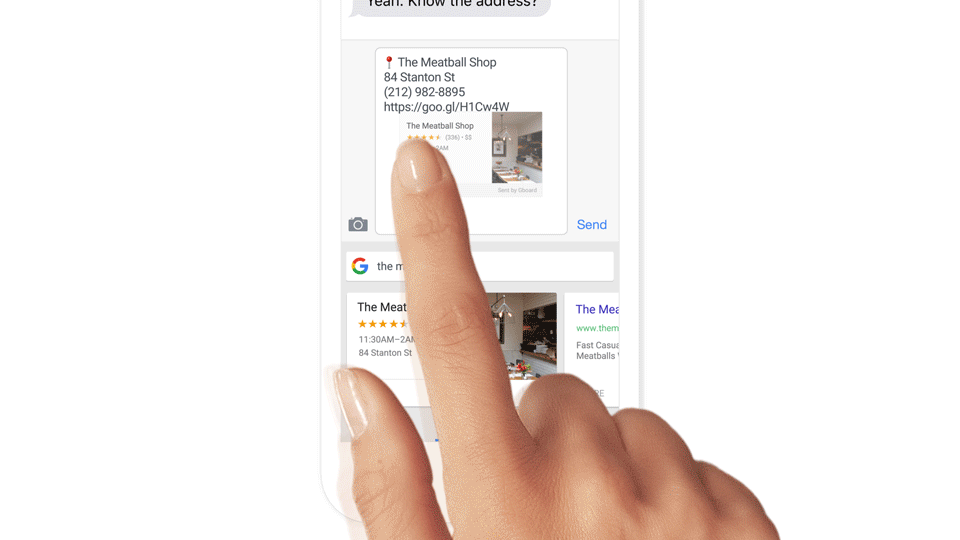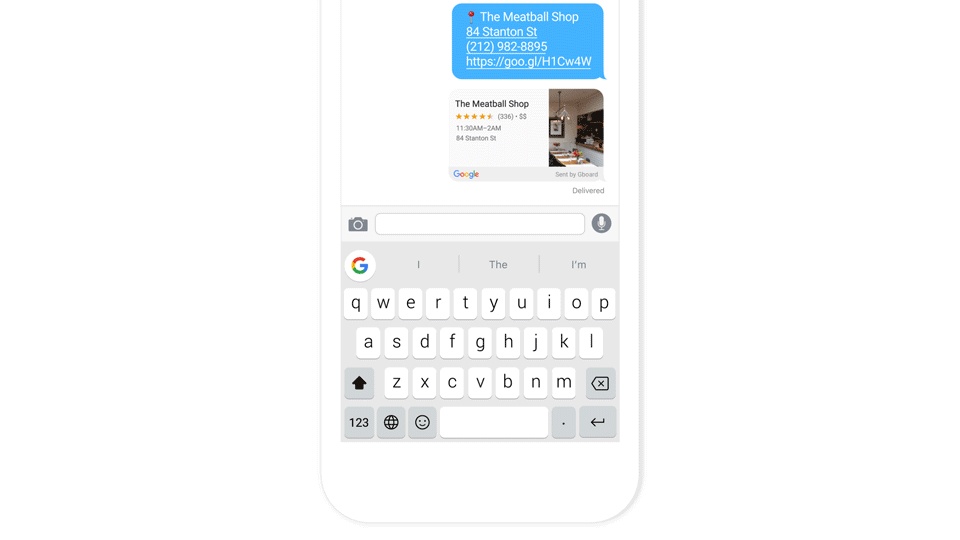
Noise Separation from the Main Commands
After detecting the keywords, the voice-enabled smart device listens more actively. Now, the system has a job of accurately interpreting the voice commands. Well, this relies on the cleanliness of the voice and accent, and this can be a more significant challenge when you are on the streets, at a restaurant, party or room full of people chattering around.
For this, numerous edge computing techniques can separate the main user’s voice from other noise. Like, beam-forming techniques use the multiple microphones of the device to narrow down the focus to the direction from where the user is speaking from, which could be a directional virtual microphone. When the user is moving the voice tracking algorithms of the smart device adjusts the signals from different microphones to keep the focus on the source of the voice.
Now, the advanced technology in the voice-enabled devices helps them process the commands from an array of microphones by cancelling out the surrounding noise. This technique is also which noise-cancelling headphones use.

The smart speakers too, use this echo/noise-cancellation technique on the device itself. It cancels out the sounds of other speakers and music with the help of microphone signals so that the smart speaker can tap the voice commands even when the surrounding noise is too loud. The smart speaker can process your voice commands in the middle of anything.
Artificial Intelligence on the Smart Device
Edge computing has given the power to smart devices like voice-enabled gadgets to use artificial intelligence on the device. This technique makes the device able to process basic offline commands by using on-device language memory processing when there is no internet available. So, you can set reminder or alarm, switch on or off the lights and security alarm, or change temperature even when the device is out of internet coverage.

Smart devices having more cutting-edge technology can also process voice as a biometric input for authenticating users. This feature prevents any random person from giving any unwanted commands to your voice-processing gadget.
Furthermore, you can skill-up the AI-enabled voice-processing device to detect your baby’s crying voice or shattering of some things to raise the alarm for informing you. You can enhance the power by adding cameras in conjunction with the voice-enabled device to get better results and crisp details. The abilities of artificial intelligence are ever-increasing, and hence, there are many interesting uses lined up.

Due to heightened demands for high-tech edge processing supremacy in the smart devices, the use of heterogeneous processors is increasing. The architectures are diversifying as the need calls for incorporating various resources on a single chip. Infusing all of these together helps in enhancing the efficiency of the computing resources and energy, thus leading to saving costs. All of the devices which have a voice interface can be bound together for performing tasks.
Making Final Statement
At present, we are getting familiar with using voice search on our smartphones and smart speakers, but with advancing edge computing and artificial intelligence, many more devices can be operated with virtual voice interfaces.
Spotify Voice
The power of the cloud and edge computing together can build up a niftier world where the devices can also perform multiple local or offline operations. The responsiveness of the smart devices will also increase as now we will have 5G, and the technological advancements will continue to happen, making our devices smarter and us, lazier! 😉
- Have You Chosen the Right Cloud Service for Migration? - December 6, 2019
- IoT Touching Your Life - November 12, 2019
- Transform and Automate Your Logistics with RPA - November 5, 2019
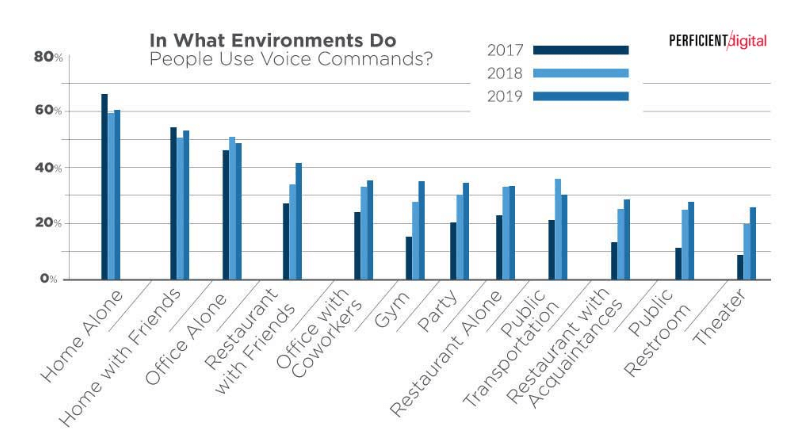
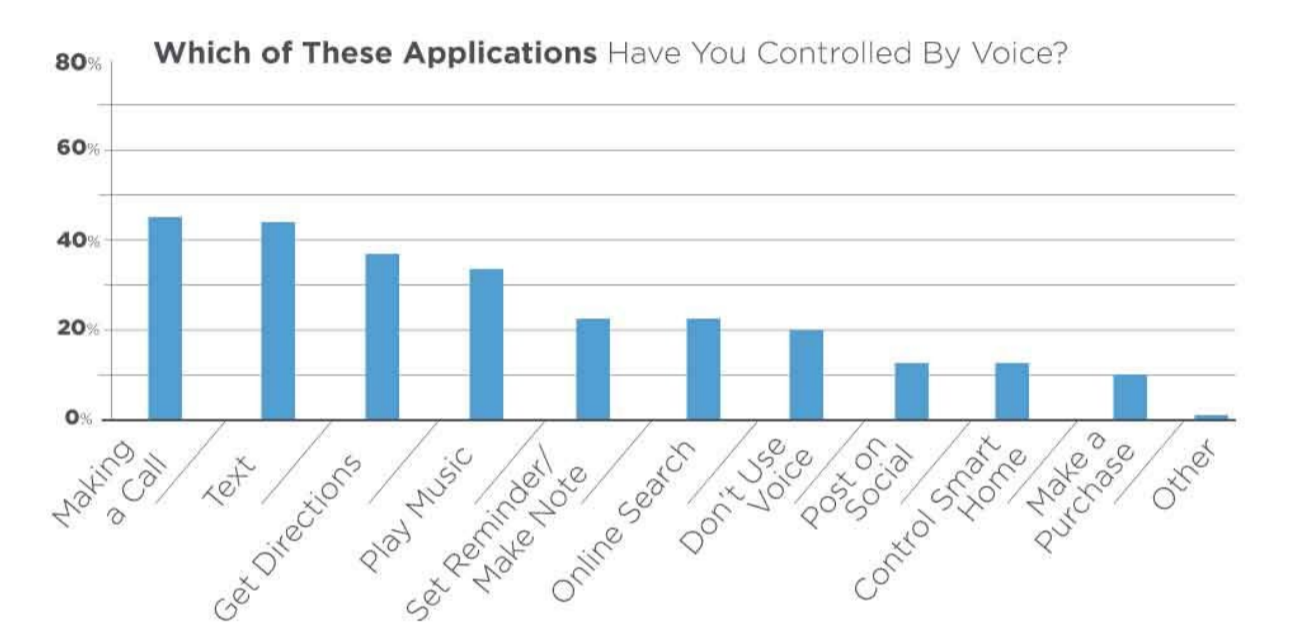
Voice search is really a hot topic among SEOs these days and many think that it's the future of search engine marketing. We're seeing an incline in number of users utlizing voice