
Cluster Computing: Definition, Architecture, and Algorithms
Defining Cluster Computing
In the most basic form, Cluster computing depicts a system that consists of two or more computers or systems, often known as nodes. These nodes work together for executing applications and performing other tasks. The users using nodes have an apprehension that only a single system responds to them, creating an illusion of a single resource called virtual machines. This concept is defined as the transparency of the system. Other essential features that are required for constructing such platforms include- reliability, load balancing, and performance.
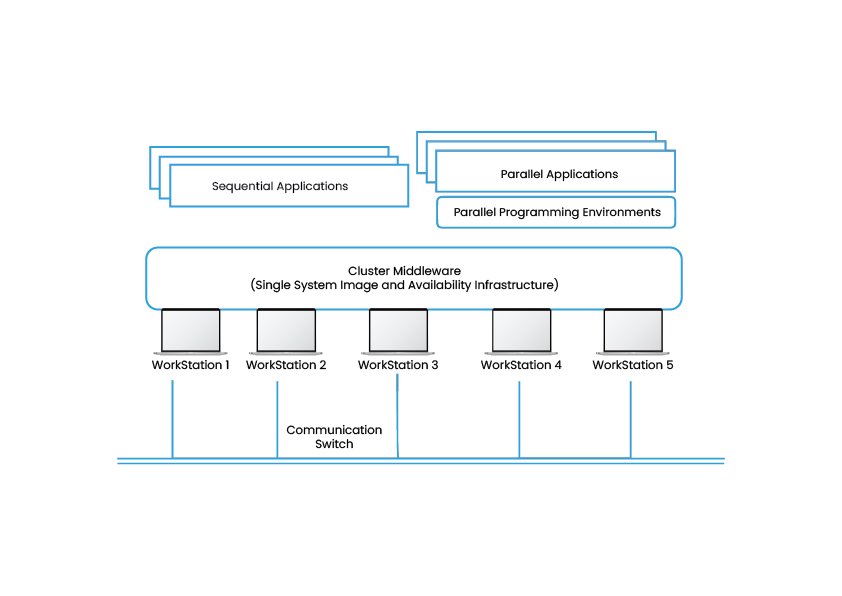
Types of Cluster
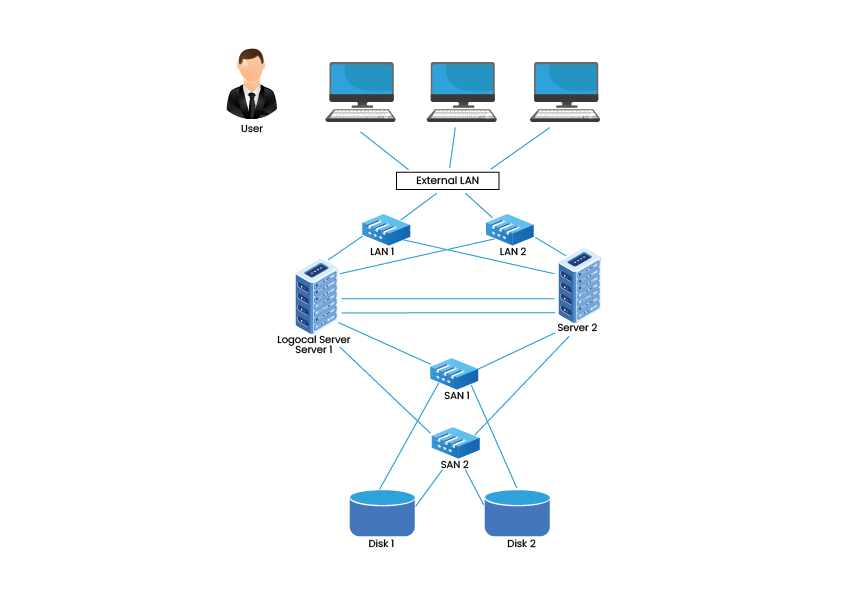
1. High Availability (HA) and Failover Clusters – These cluster models create availability of services and resources in an uninterrupted method using the system’s implicit redundancy. The basic idea in this form of Cluster is that if a node fails, then applications and services can be made available to other nodes. These types of Clusters serve as the base for critical missions, mails, files, and application servers.
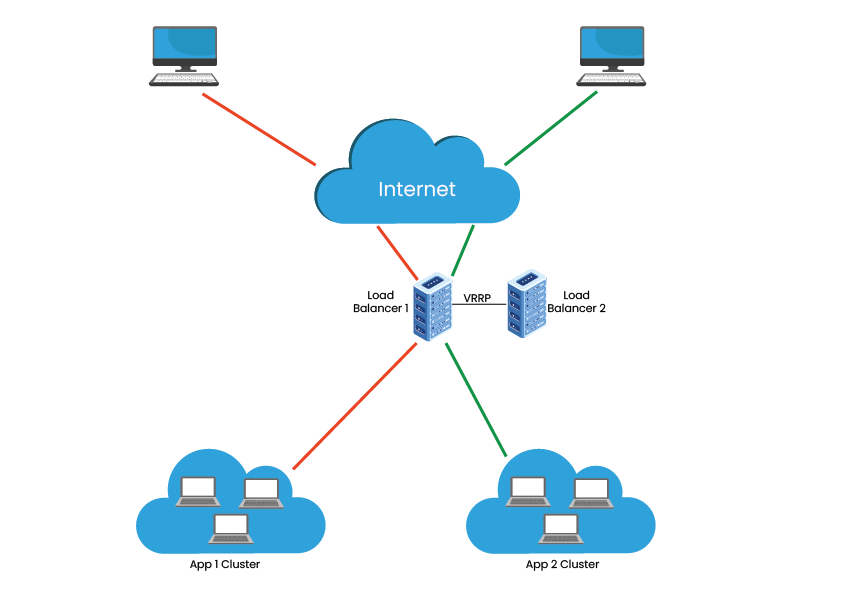
2. Load Balancing Clusters – This Cluster distributes all the incoming traffic/requests for resources from nodes that run the same programs and machines. In this Cluster model, all the nodes are responsible for tracking orders, and if a node fails, then the requests are distributed amongst all the nodes available. Such a solution is usually used on web server farms.
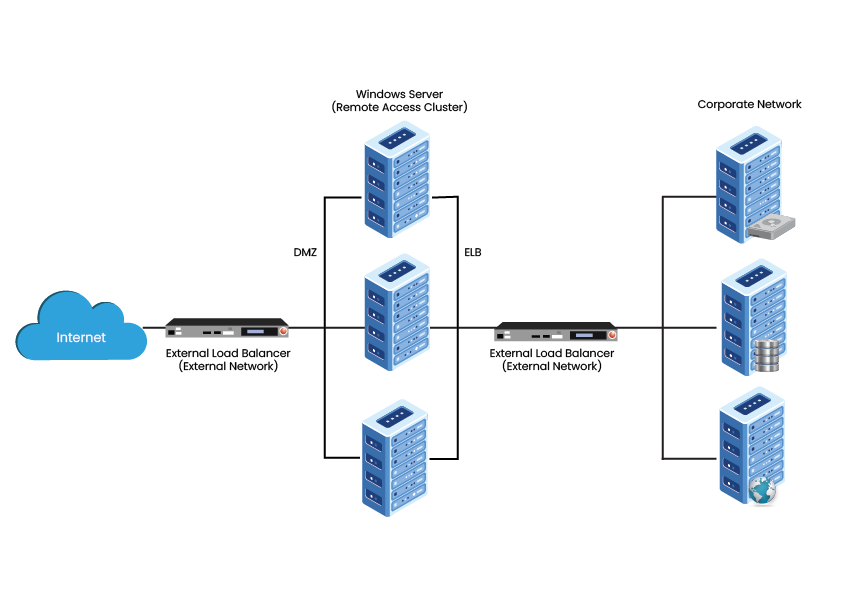
3. HA & Load Balancing Clusters – This cluster model combines both clusters’ features, resulting in increased availability and scalability of services and resources. This type of Clusters is commonly used for email, web, news, and FTP servers.
4. Distributed & Parallel Processing Clusters – This Cluster model enhances availability and performance for applications that have large computational tasks. A large computational task gets divided into smaller tasks and distributed across the stations. Such Clusters are usually used for scientific computing or financial analysis that require high processing power.
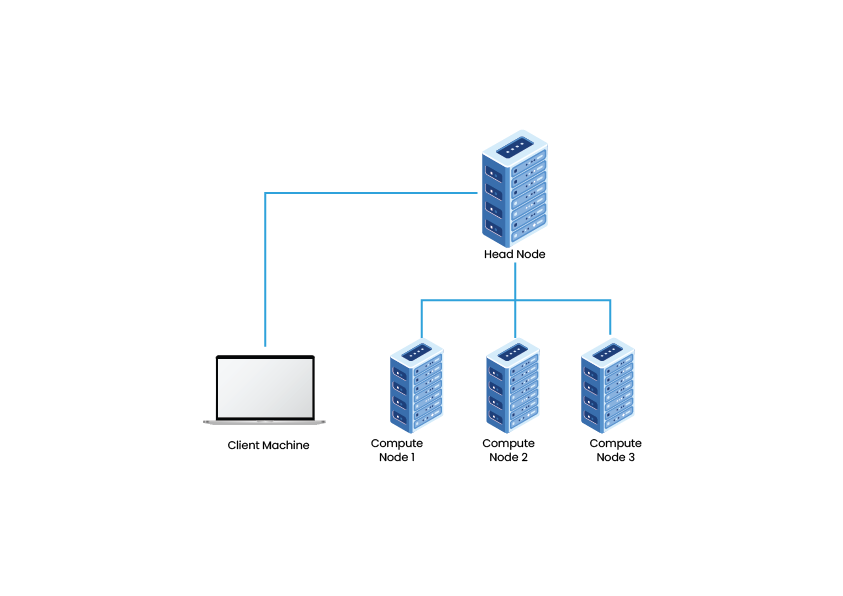
Need for Cluster Computing
Clusters or combinations of clusters are used when the content is critical, and services need to be available. Internet Service Providers or ISPs and e-commerce sites demand high availability and load balancing in a scalable manner. The parallel clusters are being extensively used in the film industry as they need high-quality graphics and animations. Talking about the Beowulf clusters, they are dominantly used in science, engineering, and finance to perform various critical projects. Researchers, organizations, and businesses use clusters to demand enhanced scalability, resource management, availability, and processing at affordable prices.
Benefits of Cluster Computing
Cluster computing offers a wide array of benefits. Some of these include the following.
Cost-Effectiveness – Compared with the mainframe systems, cluster computing is considered to be much more cost-effective. These computing systems offer enhanced performance with respect to the mainframe computer devices.
Processing Speed – The processing speed of cluster computing is justified with that of the mainframe systems and other supercomputers present in the world.
Expandability – Scalability and expandability are another set of advantages that cluster computing offers. Cluster computing represents an opportunity for adding any number of additional resources and systems to the existing computing network.
Increased Resource Availability – Availability plays a vital role in cluster computing systems. Failure of any connected active node can be easily passed on to other active nodes on the server, ensuring high availability.
Improved Flexibility – In cluster computing, superior specifications can be upgraded and extended by adding newer nodes to the existing server.
Cluster Computing Load Balancing Algorithms
Load balancing is way more than a simple redirection of client traffic to other servers. To have the proper implementation, one needs equipment with characteristics like- permanent communication check, server verification, and redundancy. These characteristics are essential for supporting traffic scalability on networking and subsequently eliminating the bottleneck or single-point failure.
Some of the common load balancing algorithms in Cluster computing are,
1. Round Robin- In Cluster computing, the Round Robin algorithm is the most commonly used one. It can be easily implemented and understood. This algorithm is best known for clusters having similar specifications. Users can opt for different algorithms in case servers have other specifications.
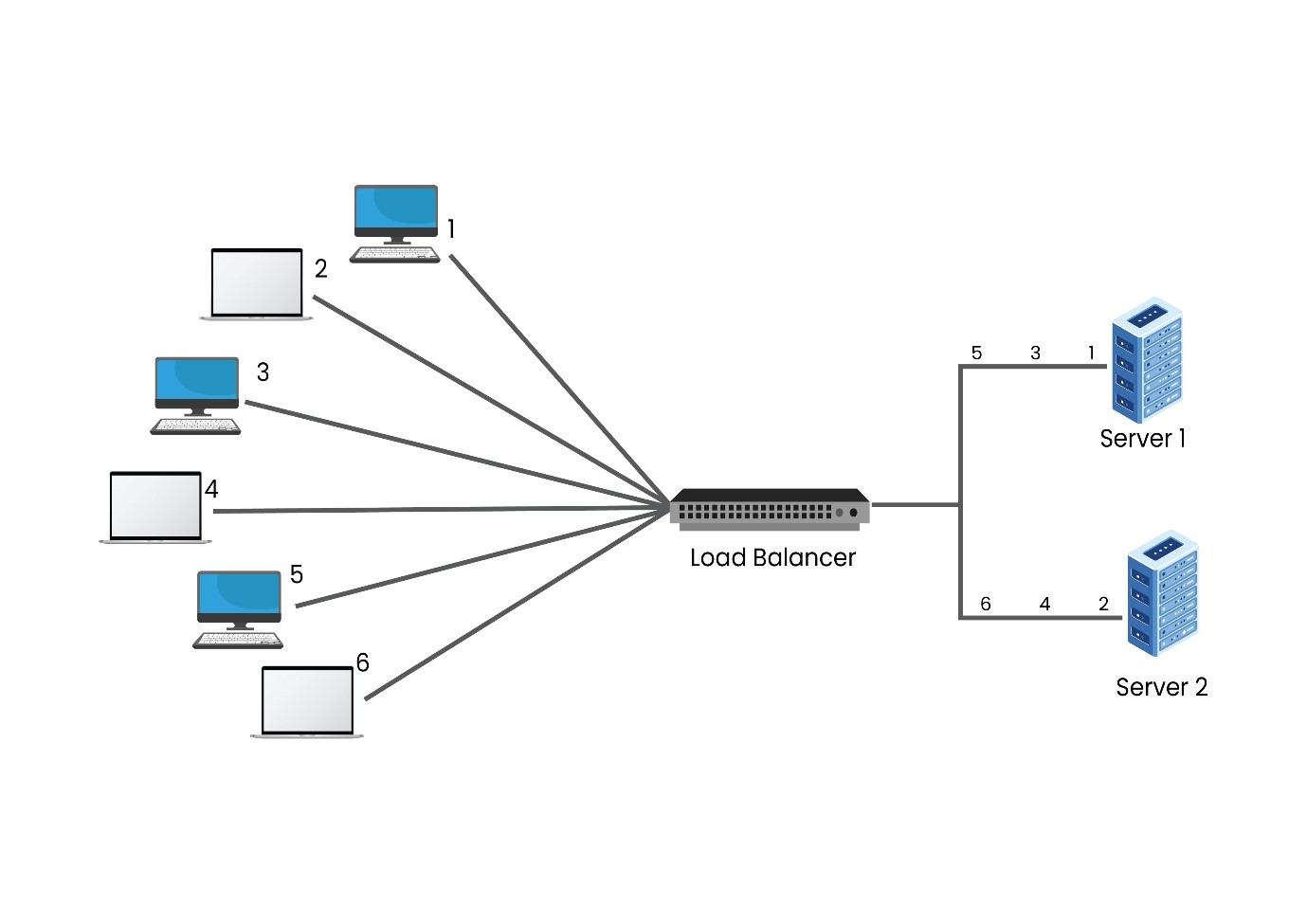
In the above diagram, there are two servers awaiting requests behind the load balancer. Upon the arrival of the first request, the load balancer will forward the request to Server 1 and after getting the second request, it is allotted to Server 2. As there are only two servers in the network, the next request will again be forwarded to Server 1—this way, the requests are sent to both the servers in a cyclic format.
It is important to note that the servers aren’t differentiated by the load balancer in the Round Robin algorithm, resulting in equal distribution of requests. If one of the servers has different specifications and workloads, then the higher workload will be directly affected by receiving cyclic requests.
2. Weighted Round Robin – The Weighted Round Robin algorithm is much like the Round Robin, however, with a slight change. In this algorithm, the server having higher specifications will be allotted more number of requests. So, how does the load balancer know which server has a higher specification? While setting up the load balancer, users might assign ‘weight’ to each node. The node having higher specifications will be allotted a higher weight.
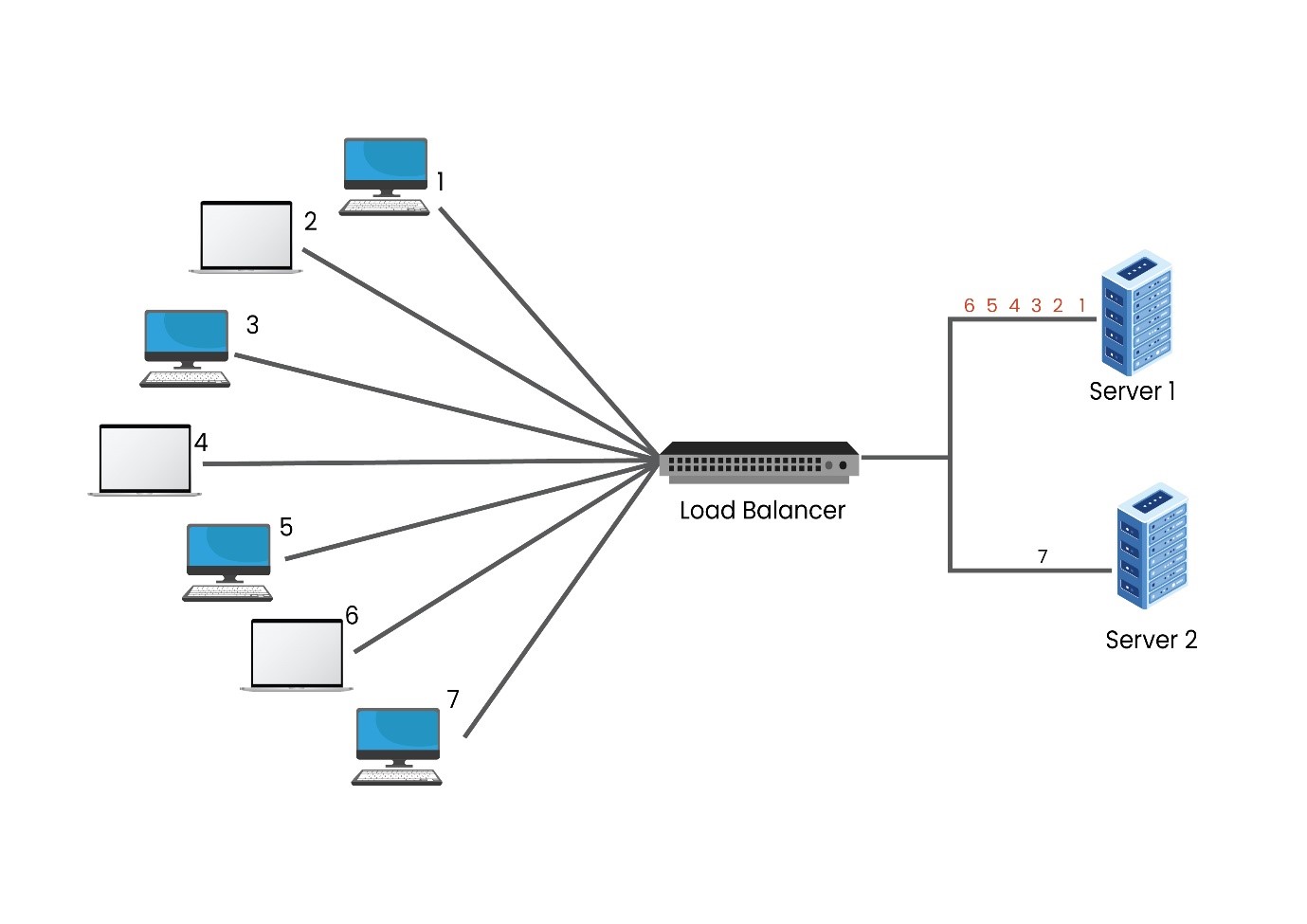
In the above diagram, if Server 1 has a capacity 6 times more than that of Server 2, the user must assign a weight of 6 to Server 1 and 1 to Server 2. After receiving the load balancer’s requests, the first-6 will be assigned to Server 1, whereas the 7th request will be allotted to Server 2. In the case of more clients coming in, the same sequence is going to be followed.
Capacity may not be the sole criteria for selecting the Weighted Round Robin algorithm. It can be used if one of the servers in the network has a lower number of connections than using an equally capable server handling critical applications, whose overloading is not a feasible option.
3. Least Connections – The Least Connections Algorithm considers the number of connections that each server currently has. Whenever there is a connection request, the load balancer determines which of the servers has the least number of connections and then the new connection will be assigned to that server.
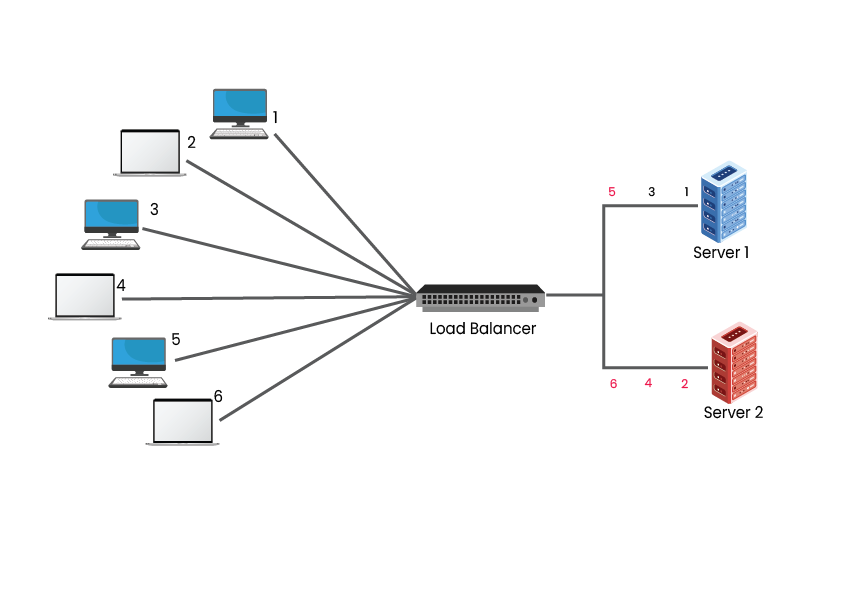
There can be situations when two clusters with the same set of specifications and servers get overloaded much faster. A possible reason could be clients opting for Server 2 to remain connected for longer than Server 1. This results in total connections in Server 1 to increase, while Server 1 remains the same, causing the resources of Server 2 to run out faster.
4. Weighted Least Connections- In this algorithm, a ‘weight’ is introduced based on each server’s capacities. Similar to the Weighted Round Robin, the user needs to define each of the servers. The load balancer implementing the Least Connections algorithm considers two things– the weights of each server and the number of clients that are attached to each server.
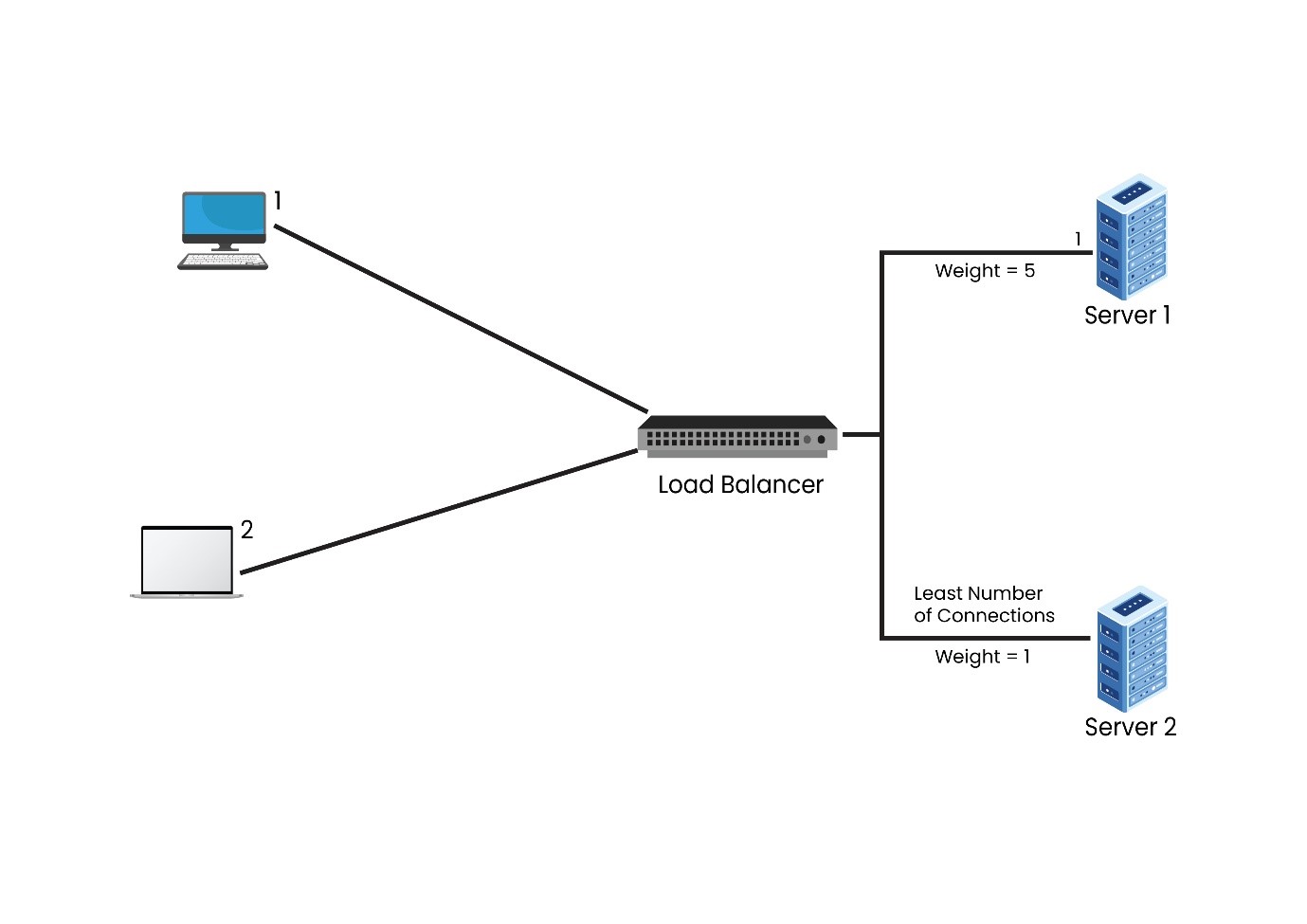
5. Random – In this algorithm, clients and servers are mapped by random, i.e., using a random number generator. In case the load balancer has a huge request load, then the Random algorithm distributes requests evenly to all the servers. Like Round Robin, the Random algorithm works well with servers having similar configurations.
Beowulf Clusters
One of the most remarkable technology advancements today has been the growth of Personal Computers’ computing performance. The Beowulf Cluster was created to achieve the rising high-performance power in certain scientific areas for developing a powerful and affordable Cloud computing system. The constant evolution of performance, processor, and collaboration between PCs and workstations resulted in decreased network processors’ reduced costs for influencing the improved high-performance clusters.
- How AI-Driven SIEM Reduces Alert Fatigue at Scale? - July 28, 2026
- Achieving Secure, Reliable Compliance with India’s Data Sovereignty Mandates - November 17, 2025
- Implementing GPU workloads in critical government application - November 12, 2025
There is definitely a great deal to learn about this topic. I really like all of the points you made.
Great post. I was checking continuously this blog and I am impressed! Extremely helpful info specifically the last part 🙂 I care for such info much. I was seeking this certain information for a very long time. Thank you and best of luck.
Good job! You thoroughly covered all the important points with this post. I would like to read more from you.
Excellent post. I was checking continuously this blog and I am impressed!
Extremely useful information. I care for such information a lot.
I was looking for this certain information for a very long time. Thank you
and good luck.
I really lucky to find this website on bing, just what I was looking for : D also saved to fav.
Very good blog post. I certainly love this site. Keep it up!
Hello there! Would you mind if I share your blog with my Facebook group? There’s a lot of people that I think would really appreciate your content. Please let me know. Cheers
Yes, you may share this blog with your Facebook group.
Thank you for sharing a wonderful article for us and I also going to share this blog with my friends.
Just desire to say your article is as astonishing. The clarity in your post is just cool and i can assume you are an expert on this subject. Fine with your permission let me to grab your RSS feed to keep updated with forthcoming post. Thanks a million and please continue the enjoyable work.
I am not that much of an internet reader, to be honest, but your blogs really nice, keep it up! I’ll go ahead and bookmark your website to come back down the road. All the best
This is the most inspiring article I have found when everyone else addressing this won’t deviate from the accepted doggerel. You have a great manner when explaining things, and I will check back as I like your writing.
The Birch of the Shadow I believe there may be a couple of duplicates, but an exceedingly useful listing! I have tweeted this. Many thanks for sharing!