
The Internet Before And After Google
 According to the Alexa site, Google is the most visited site in the world. Not coincidentally, the site created by two college friends not only changed the way we look for pages, but also the way we create our sites so that most SEO companies virtually ignores the existence of other seekers, making the sites of their clients appear on a good position or on the first page of Google. But there was a time when the Internet giant simply did not exist. In this article, we will understand how searchers were this season and how Google managed to impose, beyond the controversies that surround the site on the privacy of its users.
According to the Alexa site, Google is the most visited site in the world. Not coincidentally, the site created by two college friends not only changed the way we look for pages, but also the way we create our sites so that most SEO companies virtually ignores the existence of other seekers, making the sites of their clients appear on a good position or on the first page of Google. But there was a time when the Internet giant simply did not exist. In this article, we will understand how searchers were this season and how Google managed to impose, beyond the controversies that surround the site on the privacy of its users.
The first seekers
As you may know, the Internet has emerged in the mid-1970s. At that time, it was restricted to military and academic institutions. Its users were using services such as Telnet, FTP and e-mail. In the 1980s, popularized to the BBS (Bulletin board system), computer systems that allowed its users to read news, exchange messages, and download and upload files.
It was only in the early 1990s, Tim Berners-Lee created the World Wide Web, which would allow the exchange of information through the hypertext transfer protocol, HTTP. It is important to know, therefore, that the Internet is much greater than the web, but the web is part of the Internet that is more accessible around the world.
With the advent of internet shopping, began to appear on various websites, pages created by companies and ordinary users in the world wide web. Since the number of sites already surpassed the tens of thousands, it was necessary to have some sort of “phone book” that lets users quickly find the information they sought. There were, then, the search sites that at first were basically three types: directories, “crawlers” and meta search engines.
The directories are websites that specialize in collecting, storing and categorizing links to other sites. They run on three elements: title, keywords and description. All this information can be found in <head> section of a web page. On these sites, you type the key words you want to search and it returns the page title, its description and address. Yahoo!, one of the first search engines that appeared on the Internet. Currently, DMOZ is one of the few remaining directories, edited by humans.

Yahoo! Homepage In Mid-1997
The crawlers functioned similarly to Google. Instead of storing just the title, keywords and description, they also kept the content of the pages, making the search more accurate. The Altavista was one of the major crawlers and search engines in the higher end of the 90s.

Home of Altavista in December 1998
Already meta search engines such as HotSPot, differed from the first two because they are “leeches” in the best sense of the word. Unlike directories and crawlers, they had a database itself, but returned to the user results from other search sites.
Thus we see that, before Google, the market for web search sites was dominated by basically three types of sites: directories, crawlers and meta search engines. All of them, however, had serious flaws.
If both directories crawlers stored as links to other pages, the key question is: who will appear first when you do a search? The classification should be fair for all, therefore, could not be done alphabetically or by last registered site. Thus, most search sites were guided by the keywords contained in the page to sort your results – and that is where the issue was complicated.
Say you are looking for a Data Center in Bangalore, you would type something like “Data Center Bangalore” in the search box and the search engine would return all pages that have those words. The problem is that, this system is very easy to be deceived in both directories as crawlers.
In directories, which are searched by just the keywords and description of the site, not the content itself. Soon, it was common to make a “spam” of keywords to get more clicks. So the chance was that, you’ll find a site that is related data center and fall on a page that is without the content or, at worst, maliciously or with adult content.
Although the crawlers have partly solved the problem of directories to search the content of the page itself and not just in your keywords. Many webmasters put certain keywords in hidden text or in excess, ie, the same color as the page background, making their sites move ahead in position, making the user running the risk of finding only garbage in their research.
So, with the two main methods, needed a new way to sort the search results.
Surge Google
In 1998, the Ph.D. students Larry Page and Sergey Brim launched the project on which they were already working two years ago: the BackRub that later would be called Google, a reference to gugol, which corresponds to the number 1 followed by 100 zeros.
The uncommitted college project was to have an exponential growth in its early years soon, leaving behind all market leaders of search engine hitherto. This achievement is mainly due to two factors: its simple design and powerful algorithm.
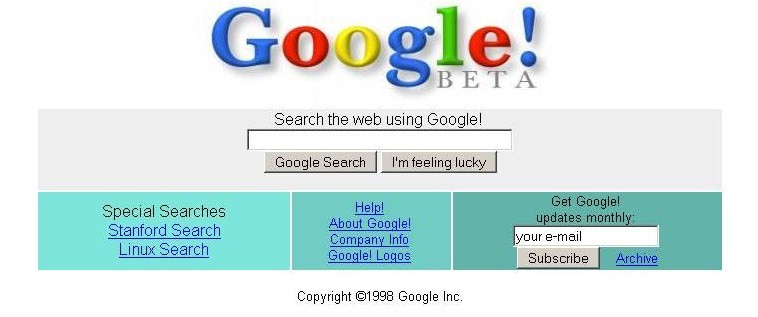
Google Homepage In 1998
As you can see by analyzing the images of the text, the initial pages of search sites in the 90’s were packed with links leading to or categories of sites, or user services, such as email and chat, or even advertisements. Google, however, decided to bet on simplicity, which would become its trademark, putting forward the user to only your main tool: the search form. The clean visual made users fall in love with Google search engine which made it popular, but it was eventually being copied by competitors, and was a major factor for the popularity of the site.
While most search engines ordered search results based on the keywords of each page, which could give rise to fraud, the folks at Google decided to follow another path, ordering pages for its importance. To this end, they developed a series of algorithms called PageRank, which assigns a value of 1 to 10 for each site, the higher the value, the more important is the site. A link from site A to site B represents a vote from site A to B. The higher the PageRank of a page, the vote has more weight and thus, based on links a page receives, determine the order of search results.
Soon, Google revolutionized the Web not just for its simple design, but mostly for its innovative way to rank pages, which silently dictated new rules to build pages. If before, due to the nature of search engines, there was great concern about the internal organization and layout of the pages, the need to appear in the top positions of Google opened a new market: SEO, which was responsible for making the internet a better place.
Privacy: The Achilles heel of the Giant Mountain View
But there are not all flowers in the success story of the search giant. From its earliest days, the company was facing problems in relation to treatment provided to the data of their users – and the list was to grow every day.
Soon it started to become popular around the world, in the early 2000s, there was a great controversy over the so-called “immortal cookie” Google. Cookies are pieces of information that websites write to your hard drive to remember your preferences. They allow, for example, you log into a page, close the browser and when opened it again, the page will be showing your profile, without the need to re-authenticate. The problem is that the cookie of Google was originally scheduled to expire in 2038, 40 years after the founding of the company! Added to the fact that the cookie assigns a unique ID to each computer and that the company records all the searches you make, it could mean that they could keep track of all your life based on your searches (currently the cookie of Google is scheduled to expire in 2014, refer to your browser.)
With the growth of the company’s increased concern about privacy: They bought the first global blogging service, Blogger, created a e-mail service itself, the gMail, one of its employees called Orkut Buyukkokten created a relationships site that was very famous in India and later the company launched Google+ to compete with Facebook and have +1 buttons – they record their tracks, whether or not you are on the network – spread all sites across virtually; The email service displays advertisements based on the content of the messages you receive – although it does not guarantee that they read your mail; Google Buzz was a complete flop and had to be disabled to prevent further complications; interpreting the terms of Google Drive service implies that all personal files that you submit become the property of the company, and, finally, the new unified terms of use, which came into force a few months ago, as did many desist from using the services that the company says is not bad – not to mention that they are behind the operating system of most smartphones in the world!
Undoubtedly, Google has managed to impose and change the web for the better. But the question that remains is: are we ready to live without it?
- How AI-Driven SIEM Reduces Alert Fatigue at Scale? - July 28, 2026
- Achieving Secure, Reliable Compliance with India’s Data Sovereignty Mandates - November 17, 2025
- Implementing GPU workloads in critical government application - November 12, 2025