All about Kubernetes
The use of containers has caused a paradigmatic shift in the way that software developers build and deploy programs. Kubernetes is an open source tool developed by Google to manage containers. The company used BORG software to manage about a billion deployments in its data centers across the world until the Kubernetes project was initiated in 2014. Kubernetes is now hosted by Cloud Native Computing Foundation (CNCF). Kubernetes have the capability of automating deployment, scaling of application and operations of application containers across clusters of nodes. It is capable of creating container-centric infrastructure. This document tries to explain the concept of containerisation and Kubernetes…
What is a Container?
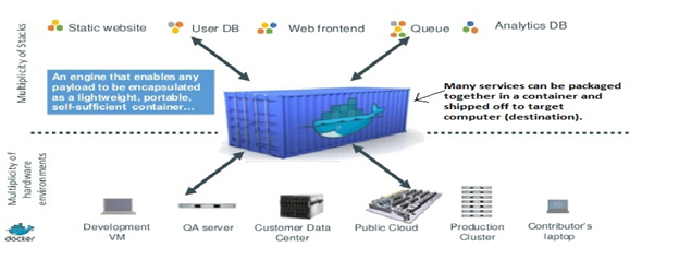
A Container is a bundle of applications with all their dependencies that remains isolated from the guest OS (client), on which they run. A software developer can package an application and all its components into a container and distribute it on the network, say internet, for public use. Containers can be downloaded and executed on any computer (Physical or VM) because they use the resources of the host OS (on which they are downloaded) for execution. Containers are very much similar to VM but depends upon what you are trying to accomplish.
What is Kubernetes?
Kubernetes is an open source tool used to manage containers across the private cloud, public cloud or hybrid cloud. It provides a platform for automating deployment, scaling and management of containerised application across clusters of nodes. It supports many other container tools as well. Therefore we can add extensions and use containers apart from the internal components of Kubernetes.
What are the characteristics of Kubernetes?
- Quick development, integration and deployment.
- Auto-scalable management.
- Consistency across development testing and production.
- Computer resources are fully utilized. Therefore you need not concern about resource wastage.
The following are the features of Kubernetes which provide management of the containerised applications. The Kubernetes API allows extensibility of extensions and containers making them scalable.
Pods
A Pod is a group of one or more containers (as a pod of peas) with shared resources and a specification for how to run the containers.
A pod contains one or more application containers which are relatively tightly coupled and can share resources of the host computer. These applications if non-containerized have to run together on one server. Pod allows these small units to be scheduled for deployment through Kubernetes (K8).
Each pod in Kubernetes is assigned a unique IP address which allows applications to use ports without the risk of conflict.
Containers within a pod share an IP address and port space and can find each other by localhost. Containers in different pods have distinct IP addresses and must have a special configuration to enable communication between them.
Applications within a pod also have access to shared volumes, which are defined as part of a pod and are made available to be mounted into each application’s file system.
Pods do not live long. They are created, destroyed and re-created on demand, based on the state of the server and the service itself. Pods can be manually managed through the Kubernetes API.
Labels and selectors
Labels are key/value pairs that are attached to objects, such as pods and nodes. Labels are intended to be used to identify attributes of objects. They can be attached to objects at the time of creation and can be added or modified at any time. Each object can have a set of key/value labels defined but each key must be unique for a particular object.

Label selector is a query against the labels that resolve to the matching objects. For example, if the Pods of an application have labels for a system tier (“front-end”, “backend”) and a release track (“canary”, “production”), then an operation on all of the “back-end” and “canary” nodes could use a label selector such as the following:
![]()
Controllers
Kubernetes system constantly tries to move its current state to the desired state. The worker units that guarantee the desired state are called controllers. A controller is a loop that drives actual cluster state towards the desired cluster state. It does this by managing a set of pods.
One kind of controller is a Replication Controller, which handles replication and scaling by running a specified number of copies of pods across the cluster. It also handles creating replacement pods if the underlying node fails. They create and destroy pods dynamically.
DaemonSet Controller is also a part of the core Kubernetes system which is used for running exactly one pod on every machine (or some subset of machines).
Job Controller is used for running pods that run to completion, say, as part of a batch job. The set of pods that a controller manages is determined by label selectors that are part of the controller’s definition.
Services
A Kubernetes Service is an abstraction which defines a logical set of Pods and a policy to access them – sometimes called a micro-service.
A Kubernetes service is a set of pods that work together. The set of pods that constitute a service are defined by a label selector. Kubernetes provides service discovery and request routing by assigning a stable IP address and DNS name to the service, and load balances traffic to network connections of that IP address among the pods matching the selector.
Example: Consider an image-processing backend which is running with 3 replicas. Those replicas are fungible -frontends do not care which backend they use. While the actual Pods that compose the backend set may change, thus, the frontend clients need not keep track of the list of backends themselves. The Service abstraction enables this decoupling.
By default, a service is exposed inside a cluster (Example: back-end pods might be grouped into a service, with requests from the front-end pods which are load-balanced among them), but a service can also be exposed outside a cluster.
Architecture of Kubernetes
Kubernetes has a Master-Slave architecture.
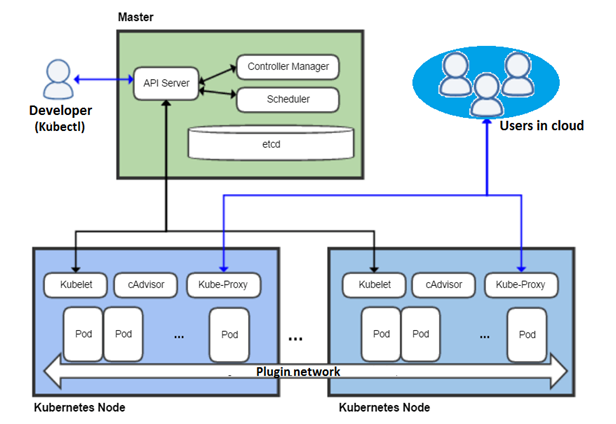
Kubectl is a command line tool used to send commands to the master node. It communicates with the API service to create, update, delete, and get API objects.
Master node
It is responsible for the management of Kubernetes cluster. This is the entry point for all administrative tasks. The master node manages cluster’s workload and directs communication across the system. It consists of various components, each has its own process that can run both on a single master node or on multiple masters.
The various components of the Kubernetes control plane (master) are:
API server
The API server is a key component and serves the Kubernetes API using JSON. The API server is the entry point for all the REST commands used to control the cluster. It processes the REST requests, validates them, and executes the bound business logic.
Controller manager
Controller manager is a daemon in which you run different kinds of controllers. The controllers communicate with the API server to create, update and delete the resources they manage (pods, service endpoints etc.).
Scheduler
The deployment of configured pods and services onto the nodes is done by the scheduler. Scheduler tracks resource utilization on each node to ensure that workload is not scheduled in excess of the available resources. For this purpose, the scheduler must know the resource requirements, resource availability and a variety of other user-provided constraints.
etcd
etcd is a simple, distributed, consistent and lightweight key-value data store. It stores the configuration data of the cluster, representing the overall state of the cluster at any given time instance. It is mainly used for shared configuration and service discovery.
Kubernetes nodes or worker nodes or minion
The pods are deployed on Kubernetes nodes, so the worker node contains all the necessary services to manage the networking between the containers, communicate with the master node and assign resources to the containers scheduled. Every node in the cluster must run the container runtime (such as Docker), as well as the following components.
Kubelet
Kubelet service gets the configuration of a pod from the API server and ensures that the described containers are up and running. It takes care of starting, stopping, and maintaining pods as directed by the master. It is responsible for communicating with the master node
to get information about services and write the details about newly created ones.
cAdvisor
cAdvisor monitors and collects resource usage and performance metrics of CPU, memory, file and network usage of containers on each node.
Kube-Proxy
Kube-Proxy is a network proxy and a load balancer for a service on a single worker node. It handles the routing of TCP and UDP packets of the appropriate container based on IP and port number of the incoming request.
- How AI-Driven SIEM Reduces Alert Fatigue at Scale? - July 28, 2026
- Achieving Secure, Reliable Compliance with India’s Data Sovereignty Mandates - November 17, 2025
- Implementing GPU workloads in critical government application - November 12, 2025