Introduction To The Concept Of Data Lake And Its Benefits
 Big data does not generate value for you. The generation of value is when we create insights that generate tangible results for the business. However, creating big data projects do not constitute simple tasks. There are many technologies, but the challenge of integrating a very diverse collection of structured and unstructured data is not trivial. The complexity of the work is directly proportional to the variety and volume of data that must be accessed and analyzed.
Big data does not generate value for you. The generation of value is when we create insights that generate tangible results for the business. However, creating big data projects do not constitute simple tasks. There are many technologies, but the challenge of integrating a very diverse collection of structured and unstructured data is not trivial. The complexity of the work is directly proportional to the variety and volume of data that must be accessed and analyzed.
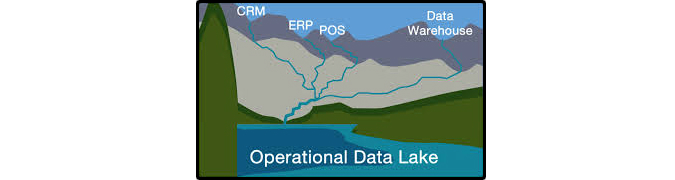
A possible alternative to this challenge is the creation of data lakes, which is a repository where it stores a large and varied amount of structured and unstructured data. The massive, easily accessible repository built on date (Relatively) inexpensive computer hardware is storing “big data”. Unlike data marts, Which are optimized for data analysis by storing only some attributes and dropping below the level aggregation date, the data lake is designed to retain all attributes, so especially When You do not know what is the scope of data or its use will be.
It is a new terminology, so there is no consensus as to its name. Some call data hub. We adopt the date lake which is most used term.
With a data lake, different data is accessed and stored in its original form and there we can directly seek correlations and insights, as well as generate the traditional data warehouse (DW) to handle structured data. Data Lake data models (or schemas) are not up-front, but emerge as we work with the data itself. Recalling that in the relational DW, the data model or schema must be previously defined. Data lake, the concept is one of “late binding” or “read schema” when the schema is built on the query time. Comes at a good time because the traditional data warehouse model has existed for some 30 years, almost unchanged. It has always been based on modeling called third normal form and that implies a single view of the truth. It worked and works well in many cases, but with the concept of big data and with increasing volumes and varieties (often unstructured) and the need to be flexible to do unplanned questions, the DW model clearly shows its limitations. It was not designed for today’s world.
For simplicity, a data lake can be imagined as a huge grid, with billions of rows and columns. But unlike a structured sheet, each cell of the grid may contain a different data. Thus, a cell can contain a document, another photograph and other cell can contain a paragraph or a single word of a text. Another contains a tweet or a post on Facebook… No matter where the data came from. It will just be stored in a cell. In other words, data lake is unstructured data warehousing where data from multiple sources are stored.
An innovative aspect of the concept is that, not having the need to define models previously eliminated much of the time spent on data preparation, as required in the current model of data warehouse or data center. Some estimates we spend on average about 80% of the time preparing data and only 20% analyzing. Significantly reduce the preparation time, we will focus on the analysis, which is what, in fact, creates value. How data is stored in its original form without going through previous formatting can be analyzed under different contexts. They are no longer limited to a single data model. In practice, is the model that companies like Google, Bing and Yahoo use to store and search huge and varied amounts of data. And before you ask, the technology that supports the data lake concept is Hadoop. The data lake architecture is simple: one HDFS (Hadoop File System) with a lot of directories and files.
The concept of a new data lake is not only the technology of a large repository but it is a model that proposes a new data ecosystem. We can think of no more restrictions in data warehouses and data minings where data models are already pre-defined, limited in the scope of possible questions. As all the data is available in date lake, we can make innovative intersections between data that may at first glance, not make sense. But an insight leads to a new question, which brings us to another insight and thus create new knowledge and generate value. Another advantage over traditional data warehouses is the ability to work in a much more simplified way with unstructured data.
Secret of the data lake is the concept of metadata (data about data). Each data entered, or as some say, ingested, the lake has a metadata to identify you and facilitate its location and further analysis. How to do this? Placing multiple tags on each die, so that we can locate all data from a given set of tags. A tagging concept advantage is that new data, new sources, can be inserted and once “tagged” shall be connected to the already stored data. No need of restructuring and redesigning of data models.
A resulting date lake enables users to make their searches directly without the need of IT sector interventions. This remains responsible for the security of data stored, but can leave business users, who understand the business itself, the task of generating insights and new thinking questions. Again, an analogy with Google. You make your own searches, no need to ask anyone to support or write them for you.
How to put data lake in a place? The first step is to build a repository where the data are stored without modification of tags. The second stage is the one that creates value and is what is called distillation of the data, where information is extracted and analyzed. But it needs to be done with some care…
At first glance, the data lake may looks like a pile of data which is out of control. An effective governance process, involving security, access control and adherence to compliance standards is required. Also, because it is still a new concept (although tags and Hadoop are not as new as well), is surrounded by hypes. The best practice is to put all the data in one place, and let the users on their account, make searches and correlations, generating insights. But we all know that between theory and practice there is a huge gap. So, before plunging into the lake, study the matter further and clearly define strategy for data lake and if it makes sense for your company, go for it.
After all, new duck does not dives deep into the lake…
- How AI-Driven SIEM Reduces Alert Fatigue at Scale? - July 28, 2026
- Achieving Secure, Reliable Compliance with India’s Data Sovereignty Mandates - November 17, 2025
- Implementing GPU workloads in critical government application - November 12, 2025