
Things You Need to Know About Machine Learning
The rise of machine learning made a big splash in the year 2018. It has
the potential to serve as a powerful extender of human cognition, and so it is
no longer a thing of future. The capability to drive better company outcomes,
including influential content creation, increased number of paid converters,
low marketing cost has proved to be helpful for B2B to B2C businesses. Machine
learning simply means enabling computers to execute tasks without human
intervention. The technology focuses on developing computer programs to access
the data and learn it for future use.
Let us see the steps to master Machine Learning Technology.
For a successful Machine Learning Model, ability to train, test and validate before deploying into production is essential. Preparing data for analytics accelerates the machine learning and data science projects delivering immersive business consumer experience. This automates the data-to- insight pipeline following the below mentioned six steps.
1. Data Collection
The data collection step of Machine Learning is essential as the quality and quantity of the gathered data will determine how good the analytical model will turn out to be. The multiple files need to be combined into a single input file. The collected data is tabulated and named as Training Data.
2. Filter Data
The step involves loading data into a suitable place and then organise for further use. The order of the data is randomised to verify if the order does not affect the predicted results.
3. Analyse the data
The filtered data is then analysed to see if the data is suitable to be used for machine learning. Later, the data is divided into training and evaluation sets. The step deals with removing duplicates, correcting errors, missing values, normalisation, data type conversions, etc.
4. Train the Model
A specific algorithm is designed to perform a particular task. The step is crucial as it encompasses the highly important decision to choose the correct algorithm for a model. The model is trained such that the results it displays are accurate. The aim to train the model is answering a question or make predictions as often as possible. The iteration process defines every step of the training.
5. Evaluate Model
Performance of the model is measured using a combination of metrics. The model is tested on the previously unused data, which helps to tune the model in a better way.
6. Parameter Tuning
Post evaluating the algorithm, improvements are made by tuning the parameters. It includes several training steps, learning rate, initialisation values and distribution.
7. Make Predictions
Prediction is the final step where a few questions are answered. You can finally detect whether the ML model can be used to predict the outcome. It gives the approximate result of how the model will perform in the real world.
Commonly Used Machine Learning Algorithms
Moving to the digital transformation, the technology has opened the doors for the tech giants to compete with each other for top data science talent. The primary aim is to enable the computers to learn automatically without human intervention or assistance and adjust actions accordingly. The graph of investments in technology is increasing every year. The technology has several algorithms, which can be applied to almost every data problem.
Let us delve in deep to see the different algorithms in Machine Learning.
1. Linear Regression
Linear Regression is based on Supervised Learning algorithm of Machine Learning. The algorithm is used to estimate real values like the cost of houses, several calls, etc. based on a continuous variable(S). It is mostly used for finding the relations between independent and dependent variables by fitting the best line. This line is represented by a linear equation Y= a *X + b and is termed as a regression line.
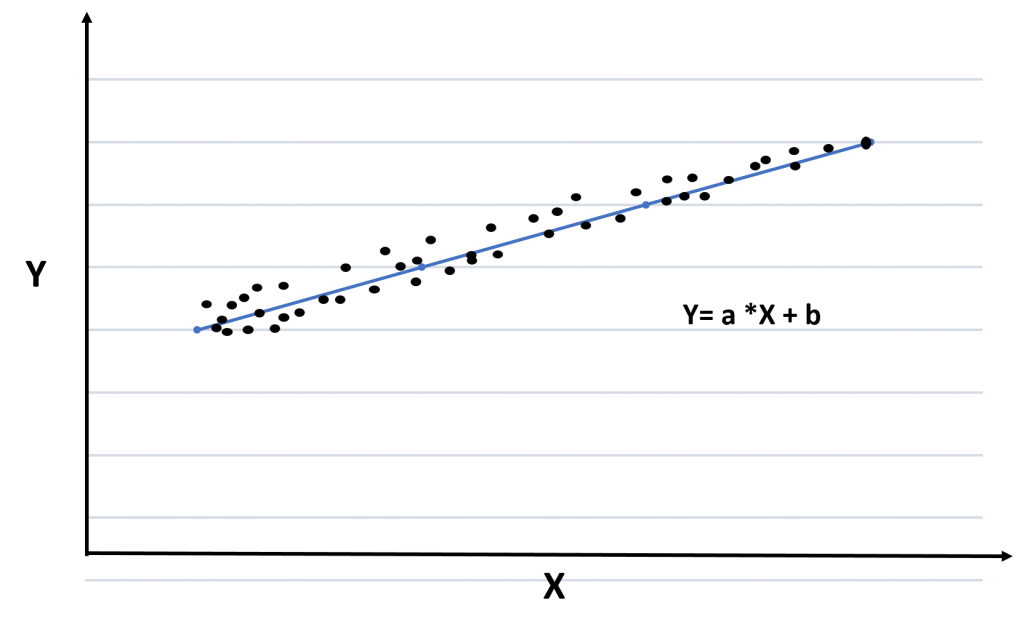
The model is trained using the below variables:
X: input training data
Y: labels to data (supervised learning)
While training a model, to predict the value of y for a given value of x, it fits the best line. The best regression line is obtained by finding the values of a and b.
a: coefficient of X
b: intercept
2. Logistic Regression
Logistic Regression is not a regression algorithm but is a supervised classification algorithm. It helps to estimate discrete values like 0/1, yes/no, true/false depending on the given set of the independent variable(s). In simple words, the output variable y can predict only discrete values for a given set of input variable x. It is also known as logit regression since it predicts the probability of occurrence of an event by fitting data to a logit function. Its output value lies between 0 and 1 as it predicts the probability. It models the data using a sigmoid function.
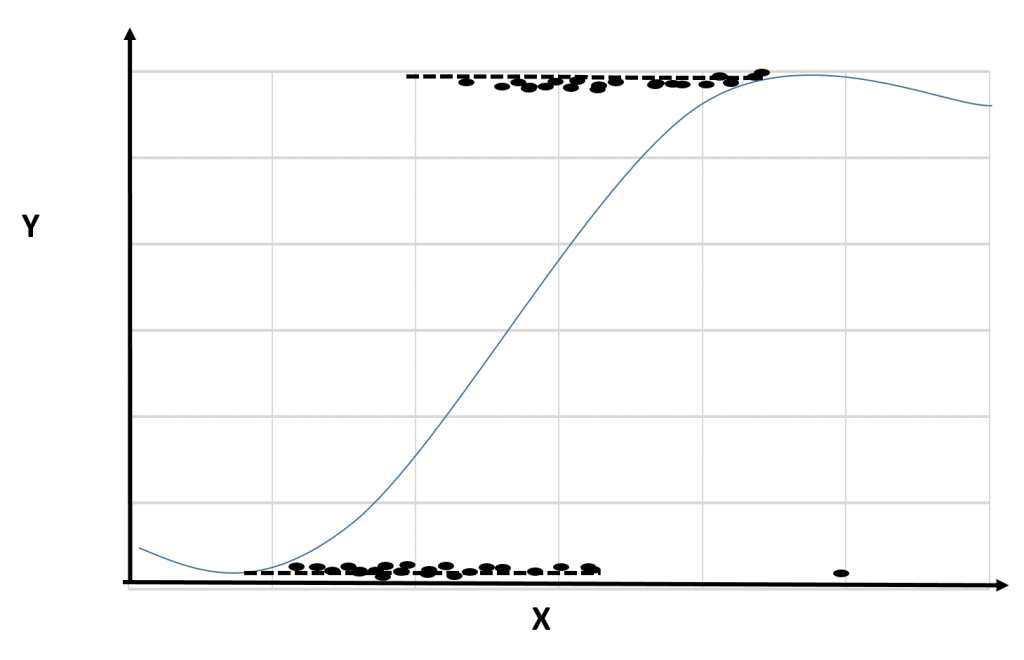
Logistic Regression is classified as:
• Binomial: The target variable has only two possible values “0” and “1”.
• Multinomial: Target variable has 3 or more variable. It means there is no quantitative significance.
• Ordinal: The target variables have ordered categories. For example, a performance score can be categorised as: “very poor”, “poor”, “good”, “very good”, “excellent”.
3. Decision Tree
Decision tree falls under supervised learning algorithm and is mostly used for classification problems. It is used for both categorical and continuous dependent variables. The algorithm involves tree representation where each leaf node corresponds to a class label, and the internal node of the tree represent attributes. It can be used to represent the Boolean function.

Assumptions to be made while using a decision tree
• Initially, the whole training set is considered as a root
• Feature values are considered a categorical while; the continuous values are discretised before building the model.
• Records are distributed recursively based on the attribute values.
• Statistical methods are used to order attributes as roots or an internal node.
4. kNN (k- Nearest Neighbors)
Though the algorithm is widely used to solve classification problems, it can also solve regression problems. It is a simple algorithm storing all available cases and classifying new cases by the majority votes of its k neighbours. The K nearest neighbour is measured by the distance function like Euclidean, Manhattan, Minkowski and Hamming distance. If K=1, than the case, is allocated to the class of its nearest neighbour.
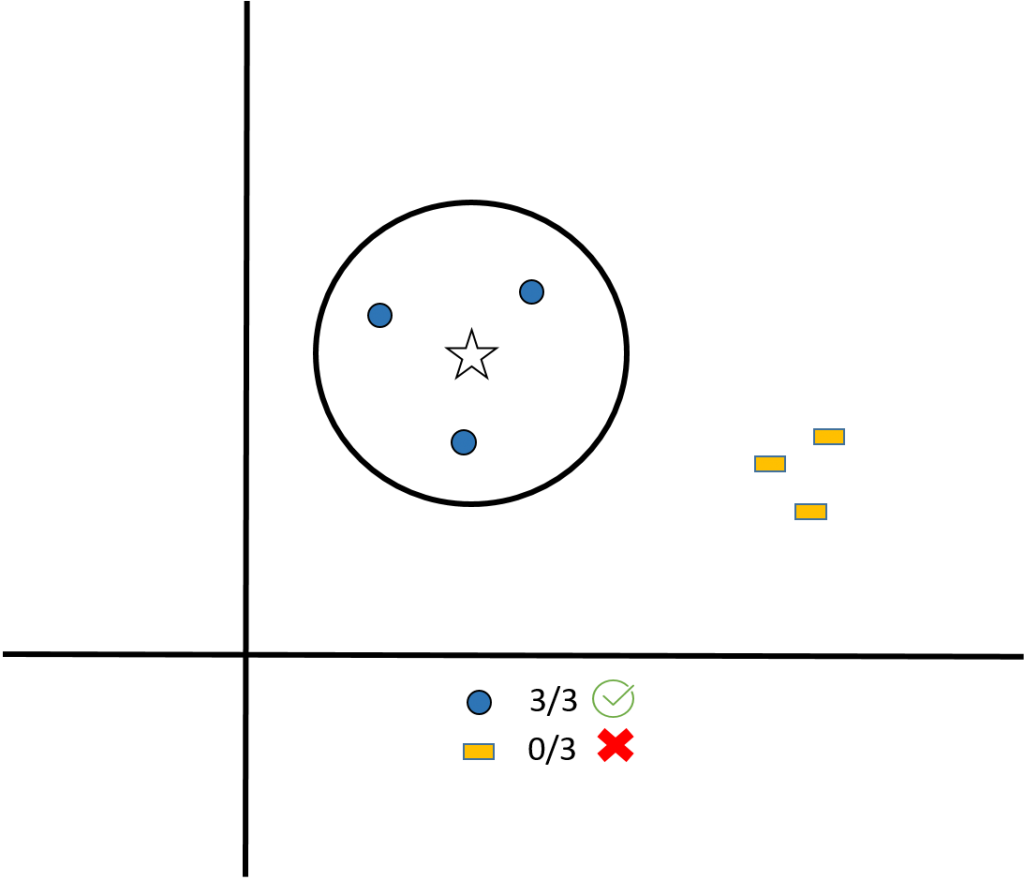
Things to consider while selecting kNN:
• It is computationally expensive
• Variables need to be normalised
• Works better on pre-processing stage before moving to kNN outlier, noise removal
5. K-Means
K-means is a type of unsupervised algorithm used to solve the clustering problem. The procedure involves classifying the given data set through several clusters (assume k clusters). Data points within the cluster are homogenous and heterogeneous to the peer groups. Every cluster in K-means has its own centroid. Sum of the square of the difference between the centroid and the data points constitutes the sum of the square value for that cluster. Adding the sum of the square values for all clusters gives the cluster solution.
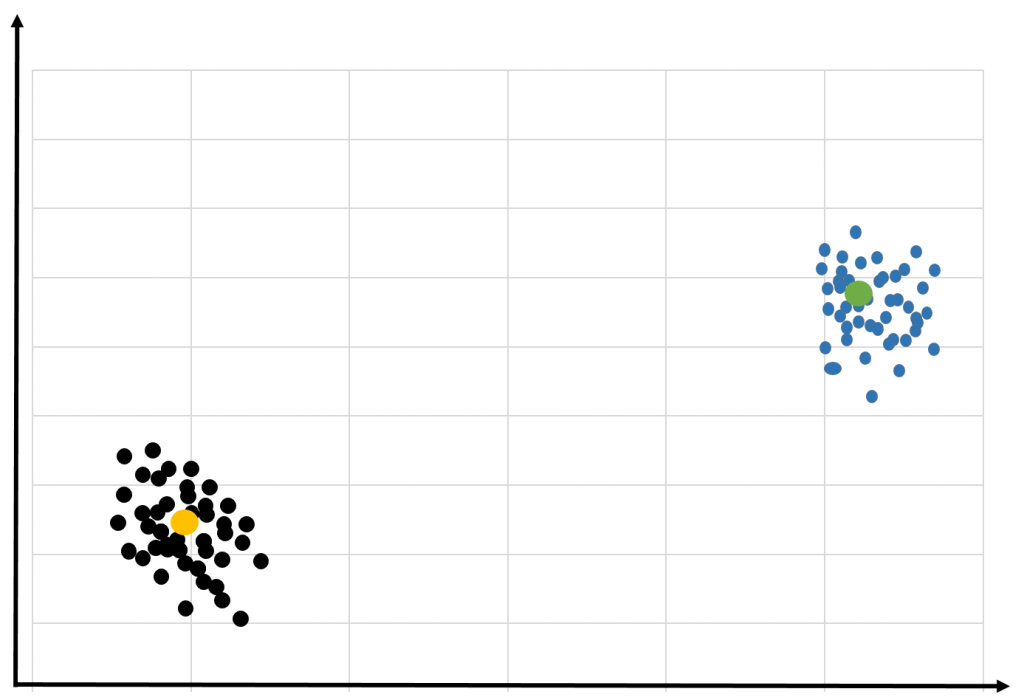
Forming of clusters:
• The algorithm picks k number of points for every centroid.
• Every data point forms a cluster with the closest centroid
• Based on an existing cluster member, the centroid of each cluster is identified. New centroids are formed.
• Post new centroid formation step 2 and 3 are repeated. Identify the closest distance for each data point from new centroids and get associated with new k-clusters. Repeat the process until the centroids don’t change.
Companies that have accepted Machine Learning
1. Pinterest
Pinterest engineers are leveraging Machine learning to keep their users pinning and sharing. In 2015, Pinterest had adopted machine learning, which led to improved content delivery.

Here is how it uses Machine Learning:
• Identifying Visual Similarities:
Pinterest processes 150 million image searches per month using machine learning. It helps the users to find the content similar to the pictures they have already pinned.
• Categorising and Curating:
It classifies the images and curates them depending on the metadata or the websites where the pictures are posted using machine learning. This makes it easier to suggest similar photos to the one requested.
• Predicting Engagement:
Pinterest is more focussed on individual tastes and habits, enabling the site to serve more personalised recommendations.
Today, ML has become an integral part of every operational step in Pinterest right from spam moderation and content delivery to advertising monetisation and reducing churn of email newsletter subscribers.
2. Facebook
Facebook is leveraging machine-learning technology to make it user-friendly, making sure the users are tuned to the application. Here is how Facebook uses ML:

• Tagging Suggestions:
Facebook uses the ML algorithm of face detection and recognition when the user is uploading a picture. The technology recognises the people in the image and suggests their names to be tagged. This reduces the human efforts of manually adding the tagging list.
• Mutual Friend Analysis:
The clustering algorithm in machine learning is used to find mutual friends. This algorithm is a part of unsupervised learning.
• Friend Suggestions:
FB uses machine learning to suggest new friends based on mutual friends circle.
Some Closing Thoughts Machine learning has already made a dent in the digitally transformed industrial world. Every model of machine learning is trained and tested differently according to the industrial needs. But, the procedure to master the technology is the same. Also, there is a wide range of algorithms available, but, the above mentioned are commonly used. The big tech giants have already adopted machine learning to stay for long in this competitive world. Machine learning will soon be an integral part of every industrial sector.
- Achieving Secure, Reliable Compliance with India’s Data Sovereignty Mandates - November 17, 2025
- Implementing GPU workloads in critical government application - November 12, 2025
- Why the BFSI Industry Needs GPUaaS Now - October 31, 2025